VELOCITI: Benchmarking Video-Language Compositional Reasoning with Strict Entailment
Darshana S*, Varun Gupta*, Darshan Singh*, Zeeshan Khan, Vineet Gandhi, and Makarand Tapaswi
Computer Vision and Pattern Recognition (CVPR), 2025
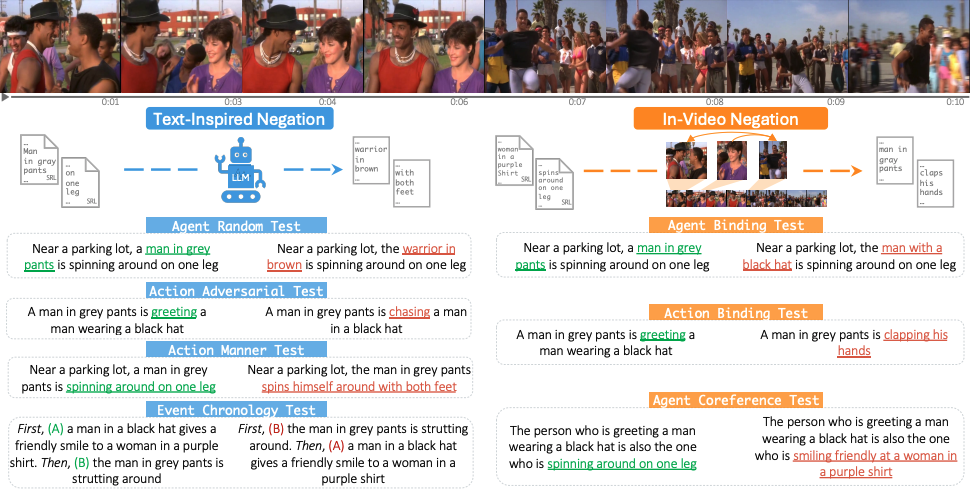
A fundamental aspect of compositional reasoning in a video is associating people and their actions across time. Recent years have seen great progress in general-purpose vision/video models and a move towards long-video understanding. While exciting, we take a step back and ask: are today’s models good at compositional reasoning on short videos? To this end, we introduce VELOCITI, a benchmark to study Video-LLMs by disentangling and assessing the comprehension of agents, actions, and their associations across multiple events. We adopt the Video-Language Entailment setup and propose StrictVLE that requires correct classification (rather than ranking) of the positive and negative caption. We evaluate several models and observe that even the best, LLaVA-OneVision (42.5%) and GPT-4o (44.3%), are far from human accuracy at 89.6%. Results show that action understanding lags behind agents, and negative captions created using entities appearing in the video perform worse than those obtained from pure text manipulation. We also present challenges with ClassicVLE and multiple-choice (MC) evaluation, strengthening our preference for StrictVLE. Finally, we validate that our benchmark requires visual inputs of multiple frames making it ideal to study video-language compositional reasoning.

 C4MTS: Challenge on Categorizing Missing Traffic Signs from Contextual CuesLecture Notes in Electrical Engineering, Springer Nature, 2024
C4MTS: Challenge on Categorizing Missing Traffic Signs from Contextual CuesLecture Notes in Electrical Engineering, Springer Nature, 2024
 Infrared Thermography and Computer Vision Based Human Respiration MonitoringInternational Symposium of Asian Control Association on Intelligent Robotics and Industrial Automation (IRIA), 2021
Infrared Thermography and Computer Vision Based Human Respiration MonitoringInternational Symposium of Asian Control Association on Intelligent Robotics and Industrial Automation (IRIA), 2021 Thermal Nostril Tracking Using YOLOv4-TinyInternational Conference on Technology, Research, and Innovation for Betterment of Society (TRIBES), 2021
Thermal Nostril Tracking Using YOLOv4-TinyInternational Conference on Technology, Research, and Innovation for Betterment of Society (TRIBES), 2021